分页数据的爬取操作
爬取肯德基的餐厅位置数据
url:http://www.kfc.com.cn/kfccda/storelist/index.aspx
分析:
在录入关键字的文本框中录入关键字按下搜索按钮,发起的是一个ajax请求
- 当前页面刷新出来的位置信息一定是通过ajax请求 请求到的数据
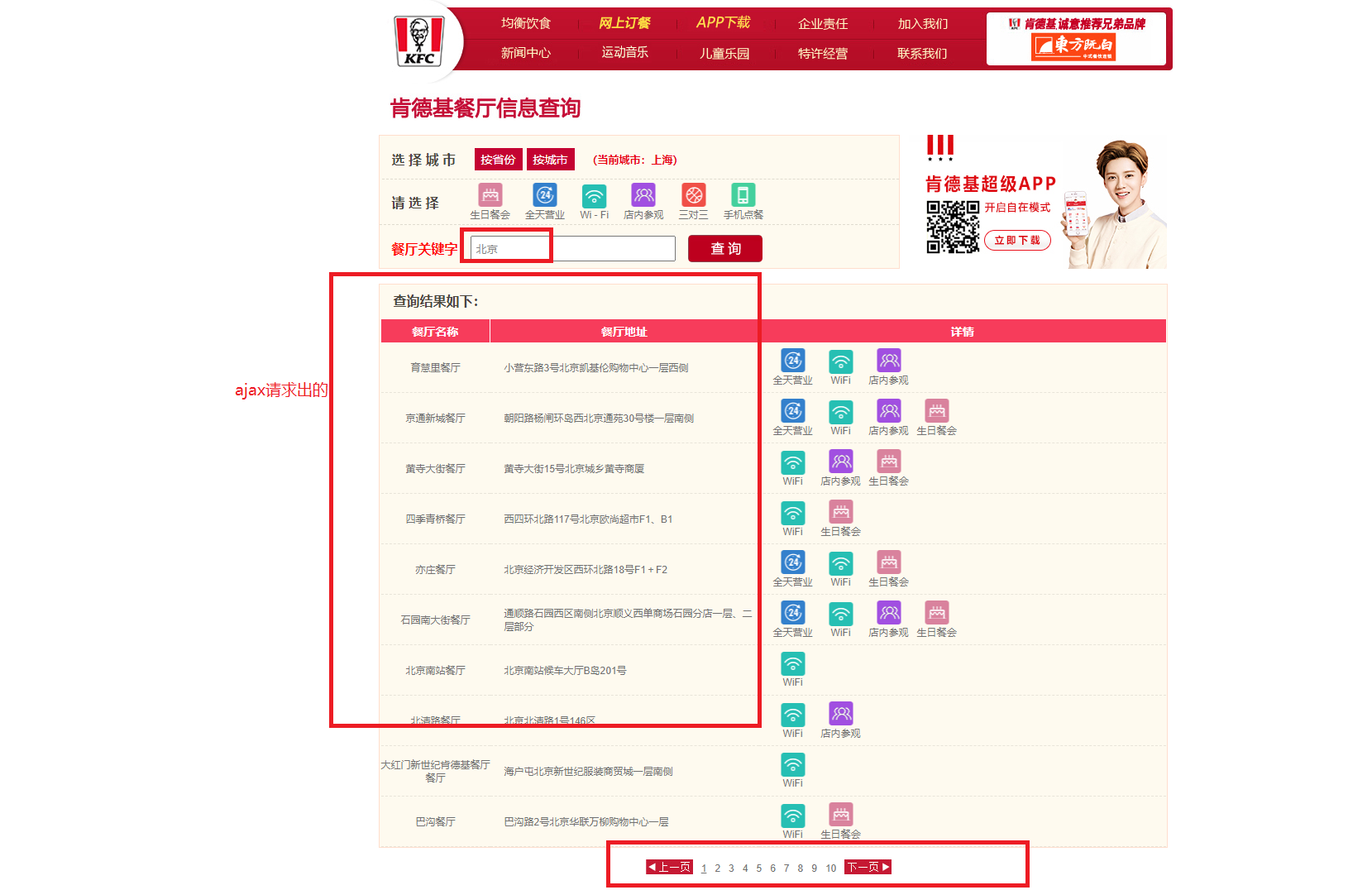
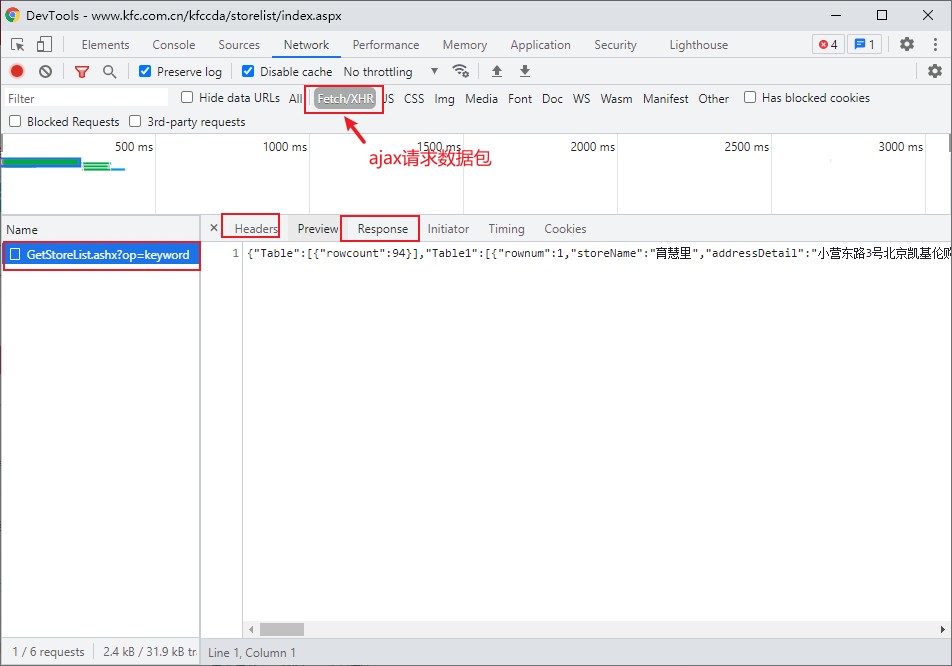
基于抓包工具定位到该ajax请求的数据包,从该数据包中捕获到:
- 请求的url
- 请求的方式
- 请求携带的参数
- 看到响应的数据
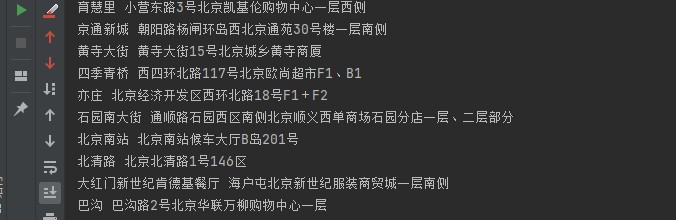
爬取的第一页的数据
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': '1',
'pageSize': '10'
}
# data 参数是post方法中处理参数动态化的参数
response = requests.post(url=url, data=data, headers=headers)
page_text = response.json()
for dic in page_text['Table1']:
title = dic['storeName']
addr = dic['addressDetail']
print(title, addr)
结果如下:
爬取多页
爬取多页直接用 for 循环,一共10页,循环10次
for page in range(1, 11):
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': str(page),
'pageSize': '10'
}
# data 参数是post方法中处理参数动态化的参数
response = requests.post(url=url, data=data, headers=headers)
page_text = response.json()
for dic in page_text['Table1']:
title = dic['storeName']
addr = dic['addressDetail']
print(title, addr)
一次性就把所有地址数据全部爬出来了
关注 Python涛哥,学习更多Python知识!